We need this because ?
We want to process tasks/jobs only once. It is hard to deliver exactly once semantics in distributed system, but we can build resiliency and fault tolerance in our system in such a way that the downstream effects happen only once.
We do this by idempotency, avoiding duplicates, setting checkpoints to recover from and retry-ability.
We want to process jobs only once because
- Processing it again may be erroneous. Ex. a refund processing task, if we refund twice we are losing money.
- We are sending messages/notifications unnecessary
- We are using unnecessary compute And many more
A job can be picked up more than once but to make sure we only process the job once and correctly. We need to add persistence to store the state of job processing and make sure the job is not concurrently processed by multiple workers.
We also use a key to manage idempotency, called idempotency key. This key is unique in a limited window of time (we don’t need it to be fully unique)
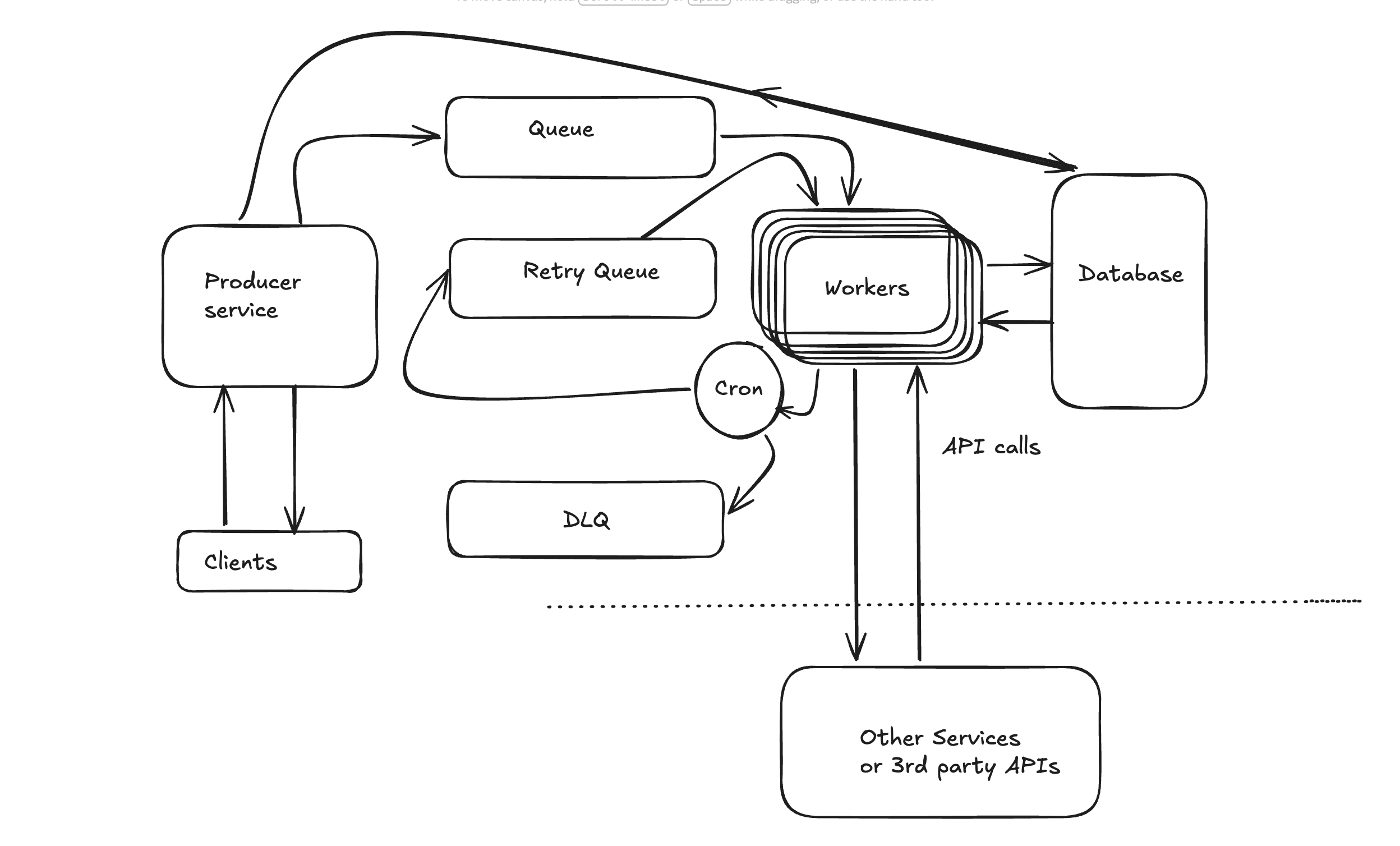
The different components of the system
- Client
- Client is the one which initiates action.
- Client connects to producer service and creates an action.
- Once client action is created, a db record is added for the job; here we make sure the status of the job is pending
- To make sure, even if the client does a second request another job won’t be created, we enforce client to send idempotency key.
- Idempotency key is unique for this particular job. (In a particular time frame)
- We can use idempotency key and userId as composite key.
- The first request with idempotency key will create a record in db and push to queue
- Producer Service
- This is the service that esposes endpoints for the clients to connect with.
- This is the service which would be responsible pushing jobs to queue add adding a record in the db
- This is the service resposible for idempotency:
- If it gets a request with new idempotency key, it responds with 201 and a db record is created and pushed into queue. (the creation of record in db is subjective choice; if we are using ephemeral queue adding a db record at this time is good option…in case of queues with durability adding to db at this point is not required)
- One more thing to note here is: if we make producer resposible for adding to DB and pushing to queue, then we should use trasactional outbox pattern.
- In case we get a second request with same idempotency key, we check if it exists in db and for a non-failure case: processing is ongoing, we just repond with 202 accepted indicating the request is still being processed
- Keeping the idempotency key same for the same request would be responsibility of the client.
- In case of complete failure, the client has to do the request again with same idempotency key and same paramenters
- Here we will also have polling endpoint which the client can poll to get the result.
- If it gets a request with new idempotency key, it responds with 201 and a db record is created and pushed into queue. (the creation of record in db is subjective choice; if we are using ephemeral queue adding a db record at this time is good option…in case of queues with durability adding to db at this point is not required)
- Queue (rabbit mq, kafka etc)
- Queue or msg-broker is the one that provides us the capability of async communication between the producer service and workers
- This can be ephemeral or persistent
- Producers will push jobs to queue and Workers will pull jobs from the queue.
- This provides a buffer in case we start facing high load
- We also use queues to build retry queues and dlq logic.
- Workers
- Workers are the one which are processing jobs.
- They can be scaled independently of producer to adjust for high load or to adjust for higher latency from downstream services.
- Database
- We use this persistence to manage the state of the job.
- It allows us to keep a receipt of the state of the system
- Jobs accepted to be processed
- Jobs currently processing
- Different stages of jobs
- Allows us to use transaction make different job stages atomic.
- Downstream Services
- These are different services or 3rd party APIs that are uitlised by workers to complete the job.
- Cron
- This is resposible for triggering retry or maeking a job as permanently failed at certain time.
- it will scan the databse for events that qualify for retry and pushed to retry queues
- We will also scan for jobs which have been retried till our RETRY_LIMIT and then will be pushed to Dead Letter Queue, where we can inspect reassons for failures.
Now coming to Jobs, here is where it gets tricky
Jobs will have multiple stages in its lifetime, generally: PENDING, INITIATED, STEP_1_DONE, STEP_2_DONE, FAILED_RETRYABLE, FAILED_PERMANENT
For each job we will use following fields
- ID
- payload
- IdempotencyKey
- userId/initiatedBy
- status: PENDING, INITIATED, STEP_1_DONE, STEP_2_DONE, FAILED_RETRYABLE, FAILED_PERMANENT
- lockedAt
- lockedTill
- retryCount
The status field denotes states of the JOB and will be a Directed acyclic graph.
We will use states as recovery points of the JOB, that means we will have to make each state change atomic.
Each job phase can be
- just db change
- Mutate foreign system: send notification
- Dependant on external services: webhook notification
- or combination of the above
We need to make sure each job state change is atomic and each stage acts as recovery point for the job to continue from in case of retry.
For example
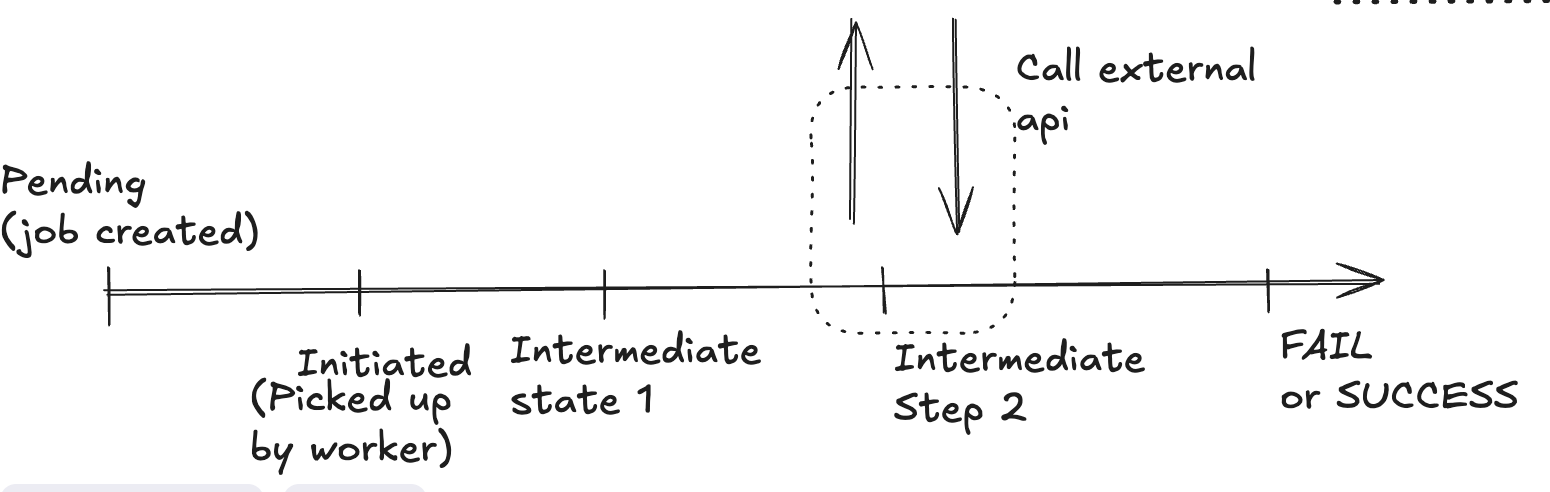
Let’s look into this diagram
- We have initially create a job
- How a job is picked up by worker
- We look for jobs which are previous stage (or retryable) and the lock is nil or expired
- It marks that the job is locked_at that particular time
- It marks that job is locked for specific period of time
- It also changes the state of job to next stage.
- Updates Iteration Count if applicable.
- We need to make sure the job selection and acquisition is atomic. This is very important
- If successful the job moves to next stage and worker does the work required for that stage
- An stage change makes sure all the operations till now are done once and correctly, even if the next state change fails, a retry will pick the job from this point only. Each stage act as recovery points.
- Now, in cases we are dependent on external API, we have to make sure the external apis called are also idempotent. ex.If our notification service is not idempotent we might send multiple notifications for same job, which is not correct.
- Finally the job reaches final stage SUCCESS or FAILURE
In case of failure
- And the retries are not exhausted the cron will scan for qualifying jobs and push to retry queue. The retry will pick up from last stage.
- And the retries are exhausted the, jobs will be passed to DLQ